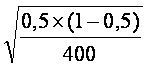[Материалы для студентов-историков]
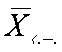 ) и выборочным (
) и выборочным ( 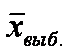 ).
). 

Точность увеличивается |
Точность уменьшается |
Предельная ошибка D уменьшается |
Предельная ошибка D увеличивается |
Доверительный интервал суживается |
Доверительный интервал расширяется |
Уверенность (надежность) уменьшается |
Уверенность (надежность) увеличивается |
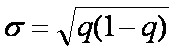
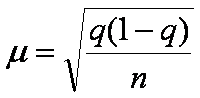
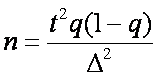

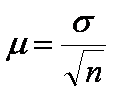
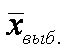 и σ ;
и σ ; 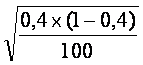 ; μ 2 =
; μ 2 =