АНАЛИЗ ВЗАИМОСВЯЗЕЙ КАЧЕСТВЕННЫХ ПРИЗНАКОВ
Типы качественных признаков
l Качественные признаки делятся на два типа: ранговые и номинальные.
l Ранговые признаки представлены категориями, для которых можно указать порядок, т.е. они сравнимы по принципу "больше-меньше" или "лучше-хуже".
l Номинальные признаки представлены категориями, для которых не определен никакой другой способ сравнения, кроме как буквальное совпадение или несовпадение.
Взаимосвязь ранговых признаков
l Меры взаимосвязи между парой ранговых признаков, каждый из которых ранжирует изучаемую совокупность объектов, называются в статистике коэффициентами ранговой корреляции.
l Эти коэффициенты строятся так, чтобы выполнялись следующие свойства:
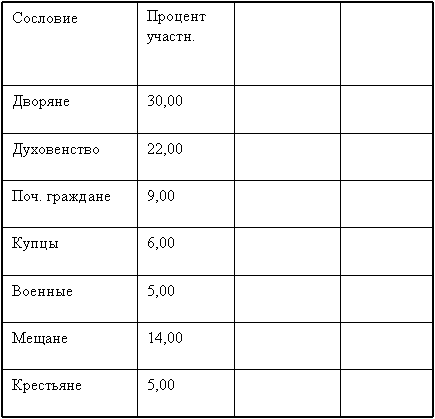
Ранжирование объектов
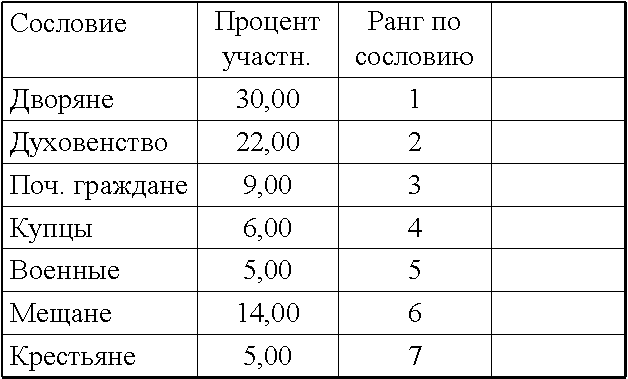
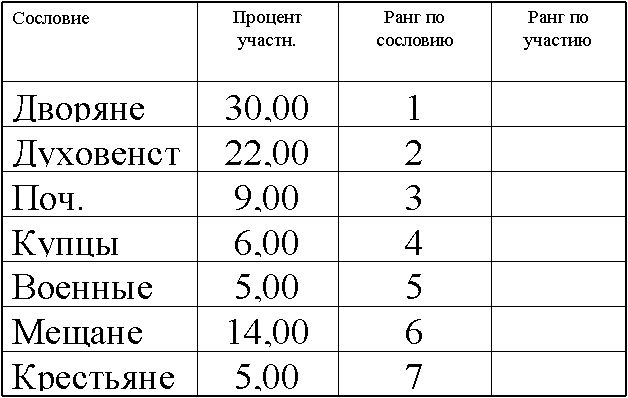
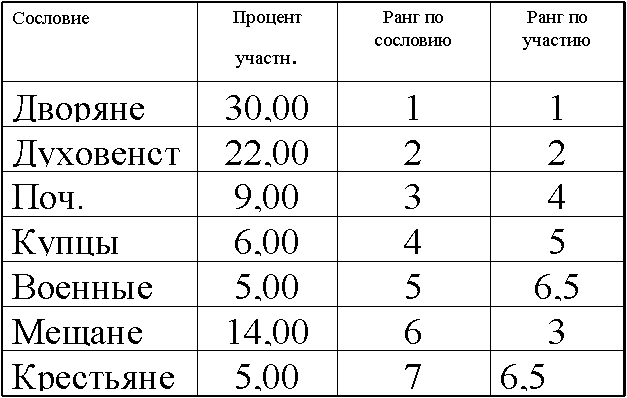
l При ранжировании иногда возникает ситуация, когда два (или больше) объектов получают одинаковые ранги (такие объекты называют связанными). В этом случае ранг связанных объектов берется равным среднему значению тех рангов, которые имели бы эти объекты, если бы они были различны.
l Например, если связанными оказались 3-й,
4-й и 5-й объекты в ранжированном ряду, то каждому из них приписывается ранг 4.
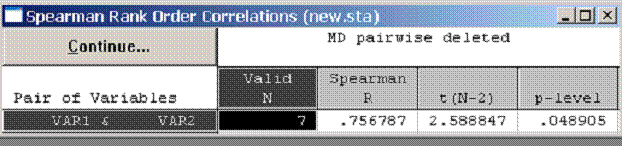
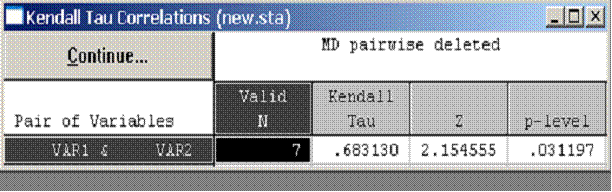
Коэффициены Спирмена и Кендалла. Значимость
l Проверка значимости коэффициентов ранговой корреляции проходит по той же схеме, что и проверка значимости коэффициентов регрессии.
l Вычисляется величина t-статистики (для коэффициента Кендалла она обозначена z) и соответствующий ей уровень значимости p (вероятность ошибки, т.е. получения в выборке таких коэффициентов при отсутствии корреляции в генеральной совокупности).
l Если значение t (или z) достаточно велико, а вероятность p, соответственно, достаточно мала, коэффициент ранговой корреляции можно считать статистически значимым, т.е. гипотеза об отсутствии корреляции (т.е. о независимости признаков) должна быть отклонена.
l На практике чаще всего применяется уровень значимости 0,05 (или 5%). Этому уровню соответствуют значения t, которые по модулю больше 2.
Применение ранговой корреляции
l Коэффициенты ранговой корреляции могут использоваться не только для анализа взаимосвязи двух ранговых признаков, но и при определении силы связи между ранговым и количественным признаками.
l В этом случае значения количественного признака упорядочиваются и им приписываются соответствующие ранги.
Взаимосвязь номинальных признаков
Таблицы сопряженности
l В статистическом анализе существуют различные методы, позволяющие изучать взаимосвязи номинальных признаков.
l Наиболее популярным из них является метод построения таблиц сопряженности (кросс-табуляция).
l Таблицей сопряженности называется прямоугольная таблица, по строкам которой указываются категории одного признака, а по столбцам – категории другого.
l Каждый объект совокупности попадает в какую-либо из клеток этой таблицы в соответствии с тем, к какой категории он относится по каждому из двух признаков.
l Таким образом, в клетках таблицы стоят числа, представляющие собой частоты совместной встречаемости категорий двух признаков (например, число людей, принадлежащих конкретной социальной группе и при этом входящих в определенную партию).
l В зависимости от характера распределения этих частот внутри таблицы можно судить о том, существует ли связь между признаками.
l Что означает связь между признаками?
l В данном примере: что означает связь между социальным статусом и партийной принадлежностью?
l Видимо, в этом случае о существовании связи свидетельствовало бы наличие определенных политических пристрастий у членов разных социальных групп.
l Формально говоря, связь номинальных признаков понимается как более частая (или наоборот, более редкая) совместная встречаемость отдельных комбинаций категорий по сравнению с ожидаемой встречаемостью – ситуацией чисто случайного распределения объектов по категориям двух признаков.
l Например, о связи между социальным статусом и партийной принадлежностью может свидетельствовать более высокая доля крестьян в партии трудовиков по сравнению с долей крестьян среди всех депутатов Думы (или же более высокая доля трудовиков среди крестьян по сравнению с долей трудовиков во всей Думе).
l Аналогично: о связи между социальным статусом и партийной принадлежностью может свидетельствовать более высокая доля дворян в партии кадетов по сравнению с долей дворян среди всех депутатов Думы (или же более высокая доля кадетов среди дворян по сравнению с долей кадетов во всей Думе).
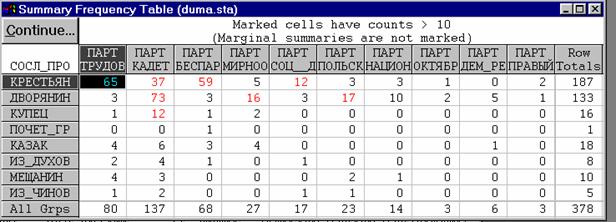
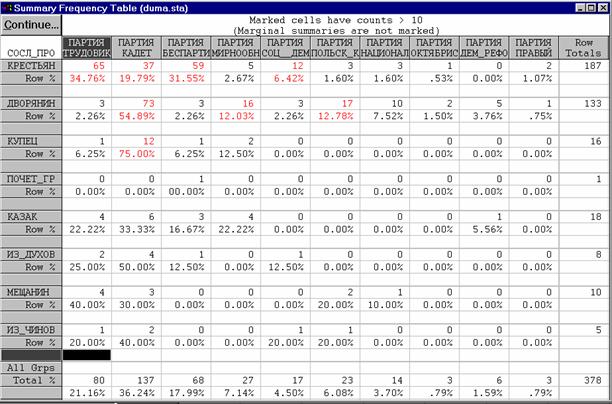
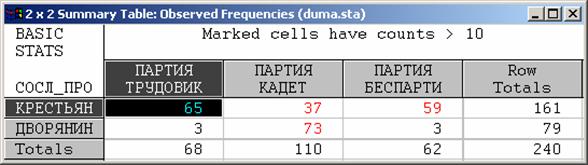
l В приведенной таблице представлены данные для 378 депутатов; среди них 80 человек (т.е. 21% – см. последнюю строку таблицы) принадлежат фракции трудовиков.
l Если бы распределение по фракциям не зависело от социального происхождения, то доля фракции трудовиков среди крестьян, дворян и т.д. составляла бы 21% численности каждой из этих групп.
Например, из общего числа крестьян в Думе (187 человек ) 21% или 40 человек "должны были бы" принадлежать фракции трудовиков.
Если же взглянуть на реальное число трудовиков-крестьян в Думе, то окажется, что их 65 человек, то есть больше, чем ожидалось.
Если подсчитать, сколько дворян принадлежало бы партии трудовиков, то окажется, что это 28 человек (21% от общего числа дворян, которых в Думе было 133).
Однако в действительности оказалось, что дворян–членов фракции трудовиков было всего трое, то есть значительно меньше, чем ожидалось бы.

Проверка гипотезы о независимости признаков
l Итак, мы собираемся проверить гипотезу о независимости фракционной принадлежности депутатов от их социального происхождения.
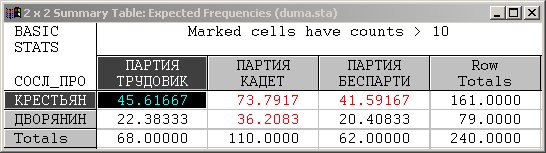
l Для этого надо сравнить в целом таблицу реальных частот с таблицей ожидаемых частот (т.е. частот, соответствующих гипотезе, что два изучаемых признака независимы).
l Для подсчета суммарного расхождения между таблицами по всем клеткам таблиц суммируют разности (точнее – квадраты разностей) между реальными и ожидаемыми частотами.
l Если суммарное расхождение равно нулю (таблицы совпадают), нет оснований отвергнуть гипотезу о независимости признаков.
l Наоборот – чем больше суммарное расхождение между таблицами, тем меньше вероятность принятия нулевой гипотезы о независимости признаков.
l Иначе говоря, чем больше суммарное расхождение между реальными и ожидаемыми частотами по всем клеткам таблицы сопряженности, тем менее вероятной является эта гипотеза.
l Сумма квадратов разностей реальных и ожидаемых частот по всем клеткам таблицы обозначается Хи-квадрат (X2). Распределение этой величины (как и известной нам t-статистики) хорошо изучено.
l То есть, для всех значений Хи-квадрат известна вероятность p того, что такие значения могут быть получены в выборке из генеральной совокупности, в которой величина Хи-квадрат равна нулю, т.е. признаки независимы.
l Значит, если вероятность p, соответствующая величине Хи-квадрат, достаточно мала, это свидетельствует о том, что гипотеза о независимости признаков должна быть отклонена, т.е. связь между ними является статистически значимой.
l Как известно, в пакете Statistica по умолчанию достаточно малыми считаются значения вероятности p, меньшие 0,05 или 5%.
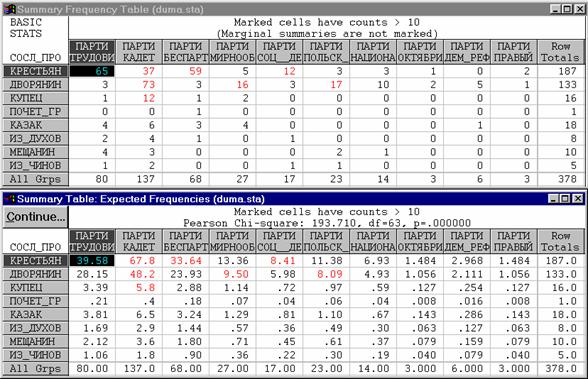
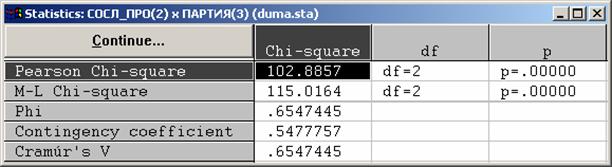
l В заголовке таблицы ожидаемых частот приводятся значение X2, которое равно 193,71, и соответствующее ему значение вероятности (p = 0,0000), которое практически равно нулю (и, очевидно, меньше чем 0,05).
l Это свидетельствует о том, что гипотеза о независимости признаков должна быть отклонена, т.е. связь между признаками является статистически значимой.
l В этом же заголовке приводится величина
df = 63. Это так называемое число степеней свободы (degree of freedom), от которого зависит вероятность p.
l Число степеней свободы для таблицы сопряженности равно произведению
(n – 1) (m – 1), где n и m – число строк и число столбцов этой таблицы.
Коэффициенты взаимосвязи номинальных признаков
l Итак, значимая величина Хи-квадрат является свидетельством связи между двумя признаками. Как же измерить силу этой связи?
l Ясно, что при отсутствии связи величина Хи-квадрат равна нулю, и это значение является минимальным.
l Существует ли максимальное значение для Хи-квадрат?
l К сожалению, даже тогда, когда связь между признаками является максимально сильной, т.е. когда каждому значению (категории) одного признака в точности соответствует определенная категория другого признака, нельзя заранее сказать, каким будет значение X2, т.к. эта величина не имеет общего для всех таблиц сопряженности максимального значения.
l Более того, так как Хи-квадрат зависит от числа степеней свободы, то невозможно сравнивать между собой значения этой величины для таблиц с разным числом строк и столбцов.
l Значит необходим коэффициент, который, подобно коэффициенту корреляции, имел бы фиксированный максимум в случае максимальной связи и позволял бы сравнивать между собой разные таблицы
Коэффициент Крамера
l Одним из коэффициентов, удовлетворяющих этим требованиям, является коэффициент Крамера V.
l Базируясь на значении Хи-квадрат, коэффициент Крамера позволяет измерять силу связи между двумя номинальными признаками.
l Коэффициент Крамера принимает значения от 0 до 1, т.е. от полного отсутствия связи до максимально сильной связи.
l В нашем примере коэффициент Крамера равен 0,27, что говорит о наличии довольно слабой связи между признаками "сословное происхождение" и "партия".
l Эта связь статистически значима, т.к. p<0,05.
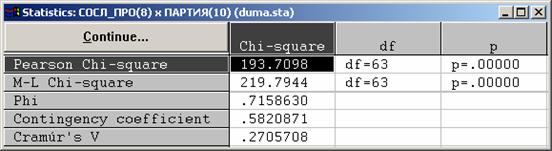
l Можно использовать значения коэффициента Крамера для сравнения силы связи одного признака с несколькими другими.
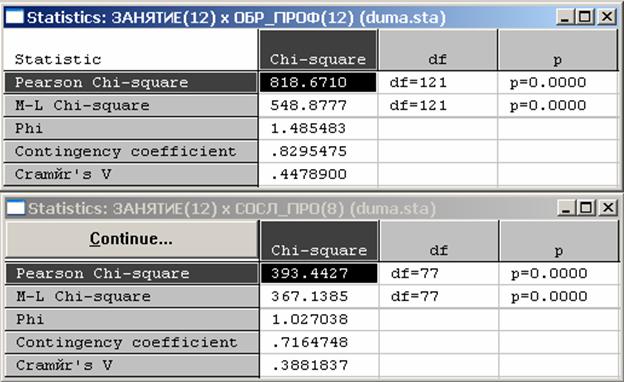
l Оба результата показывают статистически значимые взаимосвязи признака "занятие" как с признаком "профиль образования", так и с признаком "сословное происхождение".
l Однако можно сказать, что для определения рода занятий депутатов большую роль играло не их сословное происхождение, а профиль образования.
Уменьшение размеров таблицы сопряженности
l Наличие большого числа категорий по каждому из признаков затрудняет анализ таблицы сопряженности, тем более, что большая часть клеток таблицы при этом содержит либо нулевые, либо близкие к нулевым частоты встречаемости.
l Для того, чтобы устранить этот эффект, можно оставить в таблице только те категории, которые являются наиболее существенными по числу объектов, входящих в эти категории.
l Чтобы найти эти категории, надо рассмотреть в исходной таблице сопряженности итоговые строку и столбец и в дальнейшем анализировать только те категории, которым соответствуют наиболее высокие значения итоговых частот.
l В нашем примере это, с одной стороны, сословия "крестьяне" и "дворяне", а с другой – фракции "трудовики", "кадеты" и беспартийные депутаты.
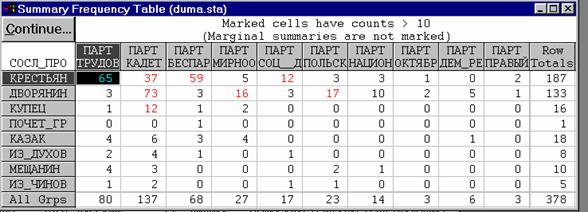
l Указав коды выбранных категорий, можно в дальнейшем работать с более удобной для анализа таблицей.
l В данном случае снова получен статистически значимый коэффициент Крамера (так как вероятность p меньше 0,05), однако величина коэффициента существенно выше – он равен 0,65.
Заключение
При этом следует учитывать, что возникают потери исходной информации, ее "огрубление". Так, для ранговых признаков теряется информация о соответствующем упорядочении объектов, а значения количественных признаков группируются в интервалы, которые при переходе на номинальный уровень измерения также оказываются неупорядоченными.
l Однако такое огрубление иногда полезно, поскольку позволяет количественные данные с грубыми ошибками трактовать как ранговые или даже номинальные. Уменьшение точности при этом компенсируется повышением надежности данных
Коэффициенты связи для признаков разной природы
| Количест-венный |
Ранговый |
Номиналь-ный |
|
| Количест-венный |
r |
r и t |
V |
| Ранговый |
r и t |
r и t |
V |
| Номиналь-ный |
V |
V |
V |